98% Faster Data Imports in Deployment Previews


Check out our previous blog post to learn about implementing Deployment Previews, a concept popularized by Netlify and Vercel in Kubernetes. This post will explain our method of provisioning them promptly, rather than keeping our engineers waiting, using PVC snapshotting.
This December, we went out and asked our colleagues to share their biggest pain points with us when it came to Developer Experience. You can think of it as user-interviews kind of thing, which was full of insights.
High on the list was the time it took for them to preview their Pull Requests. While deployment previews proved to be a success, people sometimes refrained from using them when in a hurry. The reason? A typical preview needed more than 20 minutes to become available.
So we took a better look and found out a critical bottleneck: Seeding de-identified production data in our ephemeral environments. The initial time constraints posed challenges that prompted us to take action. Join us as we unveil how we tackled this performance bottleneck, making our ephemeral environments lightning-fast (even when importing large datasets).
Previous State
Using Argo CD Waves as our deployment strategy allows us to ensure a specific order in the process of self-managed datastore deployment, data seeding, as well as application deployment, while ensuring a seamless onboarding experience.
An internally maintained application handles asynchronously both export of production data & data de-identification. A following blog post may cover the details of this operation, but to summarize, it processes production data and stores a Postgres dump, on a specific AWS S3 bucket (based on a specific schedule). Then, seeding of our self-managed datastores used to take place on demand when a preview environment is spun up. It relied on a pg_restore or equivalent operations for our other datastores, invoked by Kubernetes Jobs.
This architecture, although functional, had several drawbacks👇
- Lengthy waiting times: The whole Argo CD wave operation, required a considerable amount of time in order to be completed, which was stalling the ephemeral environment creation.
- Zero scaling: Scaling proved challenging, since data import duration was increasing proportionally to the ever increasing size of our databases.
- Error prone: Over time, several issues arose regarding permissions, migrations, etc.
The solution
We commit ourselves to continuous improvement and efficiency. So, in our software development pipeline, we explored several potential solutions to optimize the data import process.
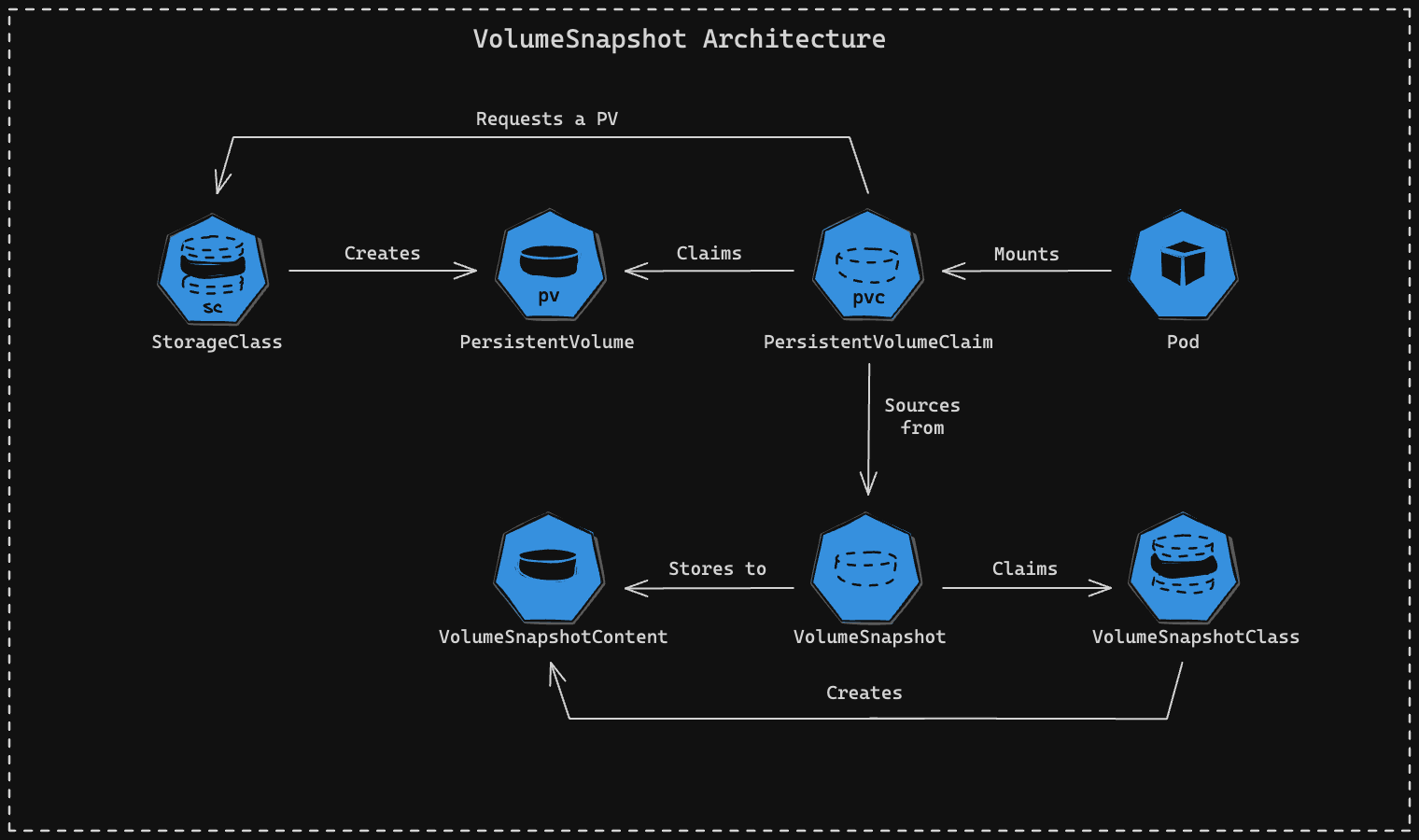
First Solution
Initially we came across Kubernetes Snapshots 📸 and the Container Storage Interface (CSI) Snapshotter as a potential solution. In our self-managed datastores, we utilize Persistent Volumes (PVs) and Persistent Volume Claims (PVCs), to dynamically create a cloud provisioned volume (in our case AWS EBS) through the CSI Driver. For each volume on a specific namespace, you can take a snapshot (depicted as a VolumeSnapshot object) with the contents of a PV at a specific point in time. On every restore, you would just refresh the PVC to initialize it from that snapshot. Albeit, the snapshots taken are namespaced, so the desired functionality to restore a snapshot in an isolated, new ephemeral environment would not work.
Final Solution
Ultimately, we landed on Velero as the optimal choice. Velero offers the flexibility to back-up any Kubernetes resource and store it in a designated storage system, such as AWS EBS in our case. It provides seamless restoration, in any chosen namespace and has the capability to map all raw files. That made it an ideal candidate for backing up PVs and meeting our diverse requirements for ephemeral environments.
The Implementation
We deployed the Velero server using Helm in our Kubernetes cluster. Additionally, we used:
- AWS EBS CSI driver to manage the lifecycle of EBS Volumes, as storage for Kubernetes PVs
- A specific VolumeSnapshotClass for the CSI driver
- Velero plugins for AWS, in order to persist and retrieve backups and backup metadata on AWS S3. Also, for volume snapshotting, which generates snapshots from volumes (during backup) and restores volumes from AWS EBS snapshots.
- Velero plugins for CSI
- A snapshot-controller in order to capture VolumeSnapshot and VolumeSnapshotContent create/update/delete events.
Guaranteeing up-to-date data
To make sure that the data which will populate the datastores of our ephemeral environments is fresh, we adjusted the aforementioned operation that anonymizes and exports data on S3.
A new, isolated namespace, was created for backup purposes and is now used as our base for each volume restore operation. Each scheduled data export seeds this isolated namespace. It uses our pre-existing data import Kubernetes Jobs, since the waiting time is not an issue there. Ultimately it performs a backup of PVs & PVCs, with Velero CLl. This results in creating the equivalent AWS EBS snapshot as well as storing a backup on S3.
This was achieved by forcing a sync operation on the ArgoCD ApplicationSet and utilizing Resource Hooks. We use PreSync hooks for our data import Jobs and a PostSync hook for our Velero CLI backup Job. This allowed us to ensure ordered execution of the aforementioned operations.
apiVersion: batch/v1
kind: Job
metadata:
name: velero-cli-backup
labels:
env: {{ $environment }}
annotations:
argocd.argoproj.io/sync-wave: "1"
argocd.argoproj.io/hook: PostSyncSeeding data into our ephemeral environments
Once an engineer adds a “preview” label on their PullRequest, the flow of ephemeral environment provisioning initiates. After the new ephemeral namespace and StorageClass are provisioned, the first Argo CD wave (a Kubernetes Job) is triggered in order to start the Velero restore operation. This process uses the generated snapshots from the already existing backup volumes in our base namespace and provisions the relative PVs and PVCs. Our datastores are then spun up and mounted on these PVCs.
Consequently, the data seeding is now implemented in the storage layer instead of the database layer, making our datastores almost instantly available to our applications.
To put that into numbers, the data import operation (based on the current size of our datasets), which previously required about 19 minutes, now only lasts a jaw-dropping max of 25 seconds ⚡. This insane optimization “translates” into a huge operational efficiency for our engineering teams by increasing productivity and enhancing the developer experience. Now, our teams can accomplish more in less time, all while preserving data integrity and consistency.
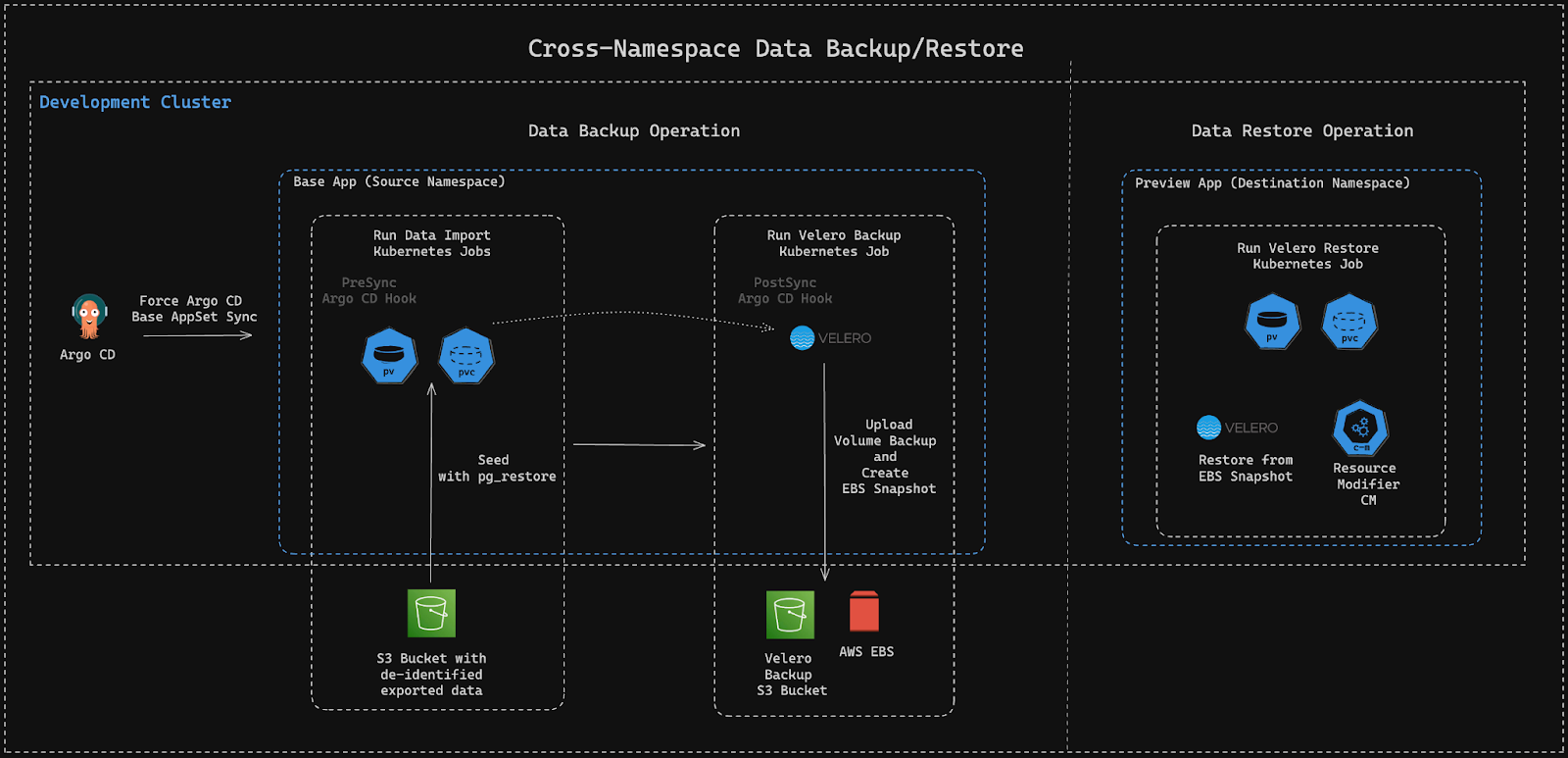
Overcoming limitations
In order to overcome the restriction of namespaced Snapshots and the usage of common StorageClasses from different namespaces by our PVCs, we utilized the ResourceModifier ConfigMap which is provided by Velero and allows us to patch any provisioned resources during restoration time. A specific ConfigMap for each ephemeral environment is deployed prior to the restoration process’ initialization, like the example:
apiVersion: v1
kind: ConfigMap
metadata:
name: resource-modified-rule-ebs-{{ $destination }}
namespace: velero
data:
resourcemodifierrule.yaml: |
version: v1
resourceModifierRules:
- conditions:
groupResource: persistentvolumeclaims
resourceNameRegex: "ebs-postgres-claim"
namespaces:
- {{ $destination }}
patches:
- operation: replace
path: "/spec/storageClassName"
value: "ebs-postgres-{{ $destination }}-sc"
- operation: replace
path: "/metadata/labels/environment"
value: "{{ $destination }}"
- operation: replace
path: "/metadata/labels/app.kubernetes.io~1instance"
value: "{{ $destination }}"Cleanup
When the TTL of 48hrs for our ephemeral environment expires, all related resources of PVs, PVCs, VolumeSnapshots and VolumeSnapshotContents are destroyed, alongside the EBS Volumes created by Velero.
Final Thoughts
Ephemeral environments play a pivotal role to Blueground's SDL, offering engineers a secure testing ground to validate changes before deploying to production. Their most important asset being their ephemeral nature, having delayed data population would strongly impede the benefits of utilizing them.
We strive to keep enhancing the tools we provide to our engineers and achieving milestones such as nearly instantaneous data availability.
Stay tuned for our next performance enhancement blog posts. 🚀