Breaking a monolith: Data replication


Introduction
The very concept of evolutionary software architecture is based on "listening" intently to the system's needs. As the system changes every day, so do its needs. Identifying the points in which architectural changes should be applied is key to the system's success.
The problem
In our case, in Blueground, it all started as a monolith, which quickly turned into a modular monorepo. At the time of writing, some of these modules have already been extracted to standalone services while others are about to.
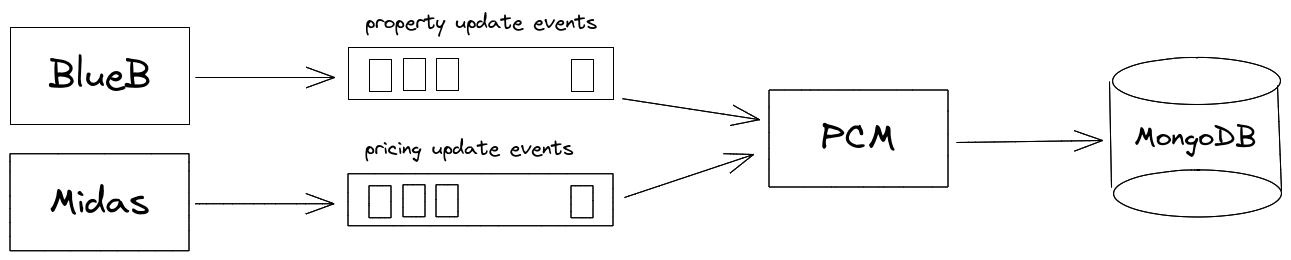
Starting off as a monolith, it's only natural to end up with dependencies on the database level when modularizing and extracting services out of it. In our case, the property information was spread through multiple tables of a relational (Postgres) database. This was handy during the early stages of the application, but as more and more flows started depending on it, problems started piling up. PCM, the service responsible for distributing the Blueground properties to the listing websites, relied heavily on the properties data. Reading these via the above-mentioned Postgres database caused all sorts of trouble.
Performance
First and foremost, performance suffered. More than 10 tables had to be joined in order to fetch the information of a single property. Fetching a few thousand properties to list (or update) them on a listing website was no lightweight operation. To make matters worse, the company was growing rapidly at the time and so did the number of properties. Apart from making some flows heavy and slow, it caused much more serious problems, such as CPU spikes.
Coupling
The amount of information that lives under a property is vast. Services like PCM only needed a fraction of it. However, they depended on all of it. This is the very definition of tight coupling. Changes in BlueB caused ripples that could result in changes in PCM, even if the changes were not related to the listing websites. This made the system holistically more rigid and fragile.
Lockstep releases
Another form of coupling was that there were cases in which BlueB and PCM should be deployed in lockstep. For instance, a database migration that would alter a table that both applications were reading was not straightforward to perform. Usually, we did this kind of deployments in multiple steps, which, of course, increased complexity, risk and slowed development down considerably.
Solving the problem with data replication
Taking a step back and looking at the problem, it was obvious that PCM needed a dedicated datastore. BlueB would still own the property data, but PCM needed to be able to act independently.
Since there was no need for real-time synchronization, it was sensible to opt for data replication. A service that replicates data is eventually consistent. Given the PCM use cases, this was totally acceptable. For instance, in case a property's price or amenities get updated it is reasonable to push this update to the listing websites within the next minute or so, instead of immediately.
Preparing for the replication
Decide on a DB technology
Naturally, the first step was to decide on the database technology that we were going to use. The main PCM use case is based on fetching multiple hundreds/thousands of properties from the database and creating a feed that will be returned to the listing websites upon their request. Consequently, we were not really interested in writing speed (we opted for eventual consistency anyway), but read speed was critical.
Additionally, we knew that the data format would be volatile. Rapid growth brings a lot of features, which bring lots of changes (additions and modifications) to the property data. Therefore, we needed a database technology that would support these changes effortlessly.
PCM is built to support horizontal scaling. Maintaining this capability was definitely high on our list.
Taking these parameters into consideration, we decided to go with a document-based database. After investigating the available solutions, we chose to use MongoDB. Some of the key reasons behind our choice were the following:
- MongoDB is available on every cloud provider
- It supports ACID transactions
- It offers a maximum document size of 16 MB, which covered both our current needs and our future aspirations
- The only drawback was that sharding seemed to be complex to implement. However, this did not really apply to our case as the order of magnitude of our properties was ~5K and sharding would not even be needed with 100K properties.
Design the model
The next preparation step was to design the model of the MongoDB document that would hold the property information. Several things should be taken into account.
- The property update event would hold generic property information. This would not be tailor-made to PCM. However, there was no reason for us to persist data that was not relevant to the listing websites that PCM was serving. Doing this would only make the model cumbersome and hard to work with. Therefore, the first step was to actually decide which data are needed.
- The property update message was naturally affected by the Postgres tables that were used to store its information. However, we needed to discard this format and come up with one that would suit our needs.
- Lastly, we needed to make sure that the model that we were coming up with was easy to extend. As new features would be implemented, new pieces of information that concern the property would arise and we needed to be able to enhance our model in a robust way.
Updating data
Having opted for eventual consistency, we decided to use RabbitMQ (which was already in place for other use cases) and have BlueB push property update events to PCM.

However, apart from BlueB, which owns the property data, there was an additional source (Midas), that owns the property's pricing information (which, for reasons irrelevant to this blog post, was decided to be part of the property MongoDB document). The catch was that the BlueB property update messages could also contain manual pricing updates (which was a design shortcoming and has been amended at the time of writing this).
Since both the property data and the pricing data may change at any given moment, this created some dreadful race condition scenarios. Updating the property's price within the next minute may be acceptable, but completely losing a price update is a serious issue.
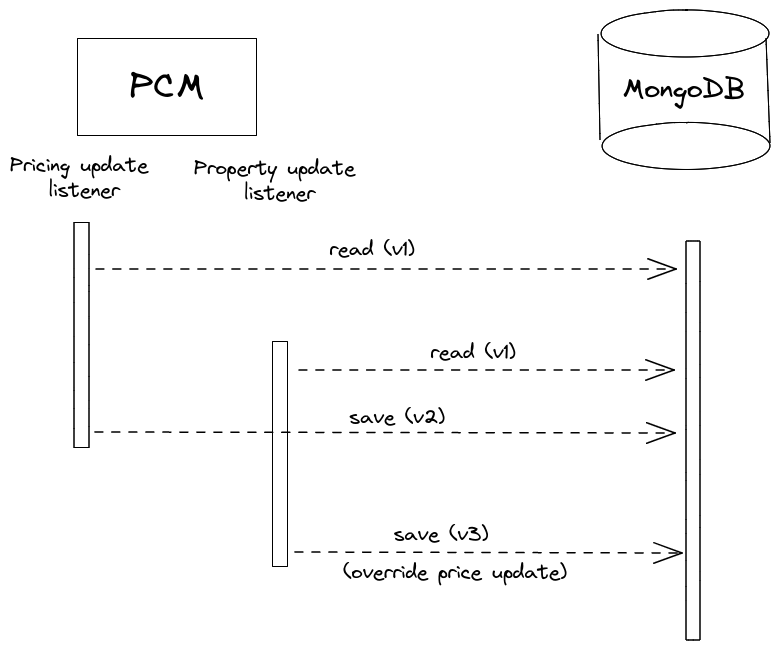
Tricky as it may be, the problem was resolved by a relatively simple approach: optimistic locking. Despite the implication of its name, this technique does not use an actual lock on the database data. Instead, it fetches the data (MongoDB document in our case), takes note of the document version and checks that the version is not changed before persisting the updated data and increasing its version. In case the document is dirty (the version number has changed since fetching it from the database), the operation is aborted and retried.

Having solved the real-time updates, we should also make sure that there was a safety net in place. For instance, what would happen in case a defective PCM revision consumed the property update messages but failed to persist their information correctly?
To solve this, we implemented a simple, on-demand data sync mechanism. This is a PCM feature that can be triggered manually, which sends an HTTP request to BlueB, asking it to publish an update event for every property in a given city. Then, PCM simply consumes the messages and updates the properties information. These syncs (one for each city) were also used in the initial rollout of the data replication feature, as it would not have made sense to wait for every single property to be updated.
Release
Because of the nature of the problem, we were able to deploy in a relatively safe way, which consisted of 3 steps.
Start the replication
The first step was to enable the data replication. This resulted in idle data in the PCM MongoDB. In this way, we were able to run our sanity checks against the replicated data until we were satisfied with the quality of the replication. In case adjustments were needed, we would be able to apply them with a minimum risk of causing production issues.
Switch a listing website
As soon as we were confident that the data were being replicated properly, we switched a single listing website. That basically means that the property feed that was being provided to this channel originated from the MongoDB data, rather than the BlueB Postgres data. This sounds a lot like switching a feature toggle. However, in reality, it wasn't that easy. Part of the feed had to be reimplemented. In specific, everything beyond our persistence architectural boundary had to work with fetching data from MongoDB and, given that the data format was altered, the converter responsible for the feed had to be modified too.
Switch all the listing websites
Serving a listing website from our MongoDB data meant that the feature was essentially in production. The remaining step was to gradually switch all channels to the new data source.
Results
Dedicating all this effort and going through so complicated and risky modifications would not make much sense if there wasn't a way to actually measure the impact on the application. Therefore, we will briefly discuss the merits that this data replication feature brought on the pain points that were listed at the beginning of this post.
Performance
Prior to the data replication, the response time to the requests of some listing websites was considerably large. After switching all the channels to our MongoDB, we noticed huge improvements. The biggest one was an improvement of 95.5%. Below, a table presents some of the most impressive cases:
| Channel | Postgres | MongoDB | Improvement |
|---|---|---|---|
| Nestpick | 44 secs | 2 secs | 95.5% |
| 35 secs | 2 secs | 94% | |
| Zumper | 33 secs | 5 secs | 84% |
| Property Finder | 12 secs | 4 secs | 66.6% |
| OLR | 12 secs | 3 secs | 75% |
| Streeteasy | 8 secs | 1 sec | 87.5% |
Coupling
Unfortunately, there is no straightforward way (that we know of) to measure the degree of coupling, but in this case, the result is evident. The reason is that by the time of writing, PCM is a completely independent service. It is removed from the modular monorepo and it is 100% autonomous. Of course, such a thing would be impossible back when the property data were shared on the database level. Therefore, replicating the data was a major milestone in the journey to decouple BlueB and PCM.
Conclusion
Part of the agile software engineering mindset is the continuous adjustment of the system architecture. In Blueground, we have come a long way on this journey. A major step on the way was replicating the property data from the service that owns them to one that just uses them and needs to act independently.
After identifying the problem and deciding to solve it with data replication, MongoDB was selected, the model was designed and the challenging problem of updating the data from multiple sources was solved. The release was performed in a 3-step fashion and the results assured us that the solution that was given to the original problem was very effective.
Glossary
- Property: a unit, offered for leasing by Blueground
- Listing website: a website that advertises properties for leasing (e.g. Airbnb)
- PCM: a service, which is responsible for distributing the Blueground properties to the listing websites
- BlueB: a service, which owns the property information
- Midas: a service, which owns the dynamic pricing information for all properties