Rustic Witcher: Reimagining data anonymization


At Blueground, the majority of our services require data for testing end-to-end user journeys, whether client-facing or operational. Consequently, we need to de-identify PII from production data to provide our engineers with realistic datasets. This approach ensures our pre-production systems mirror the behavior of production environments in terms of data volume.
To address this need, we developed an in-house solution a few years ago. This solution extracts data from production RDS instances and processes it through Debezium's ecosystem, converting it into Kafka messages. Subsequently, Simple Message Transforms (SMTs) de-identify PII data before the transformed messages are stored in a temporary Postgres instance. The de-identified data is then exported from this ephemeral Postgres instance and uploaded to an S3 bucket, making it readily available for data import into our pre-production systems.
The previously mentioned solution was effective for the data volume and number of databases we managed at the time. However, as we introduced new microservices, the number of databases and rows increased significantly. This growth caused the data export process to exceed two hours for a fresh export. Additionally, we required more powerful CI instances to reduce the time needed for data export and de-identification. Ultimately, we concluded that this solution was no longer scalable, necessitating the development of a new method for data de-identification that could accommodate our current and future needs.
Enter AWS DMS
We utilize AWS Database Migration Service (DMS) for all our production RDS instances to create a data landing zone for our Business Intelligence (BI) department. This prompted us to consider, "What if we could leverage this process to generate data for our pre-production systems?"
DMS can export data as .parquet files into a designated S3 bucket, a widely used data format that we could potentially manage. However, we lacked a method to de-identify data in this format and subsequently write it back to a temporary Postgres instance.
Enter Rustic Witcher 🦀
With these requirements in mind, we began designing a new internal tool named "Rustic Witcher." The name reflects our use of the Rust programming language and is inspired by the predecessor tool, "Data Witcher."
Why Rust?
- Flexibility
- Adapts to various use cases, from systems programming to web development
- Resource Management Efficiency
- Ensures memory safety and performance
- Concurrency
- Efficient and safe concurrency model for high-performance applications
- Modern Technology
- Incorporates the latest advancements in programming language design
All these factors were critical for us, and since we needed to reduce the time required for a fresh data export, our initial experiments confirmed that we could achieve significant gains in performance optimization and cost reduction.
We proceeded to design a new implementation from scratch, ensuring it was highly parallelized to efficiently read .parquet files into Polars DataFrames. This implementation de-identifies the data based on a newly introduced configuration format, allowing users to specify which columns to de-identify and the method of de-identification.
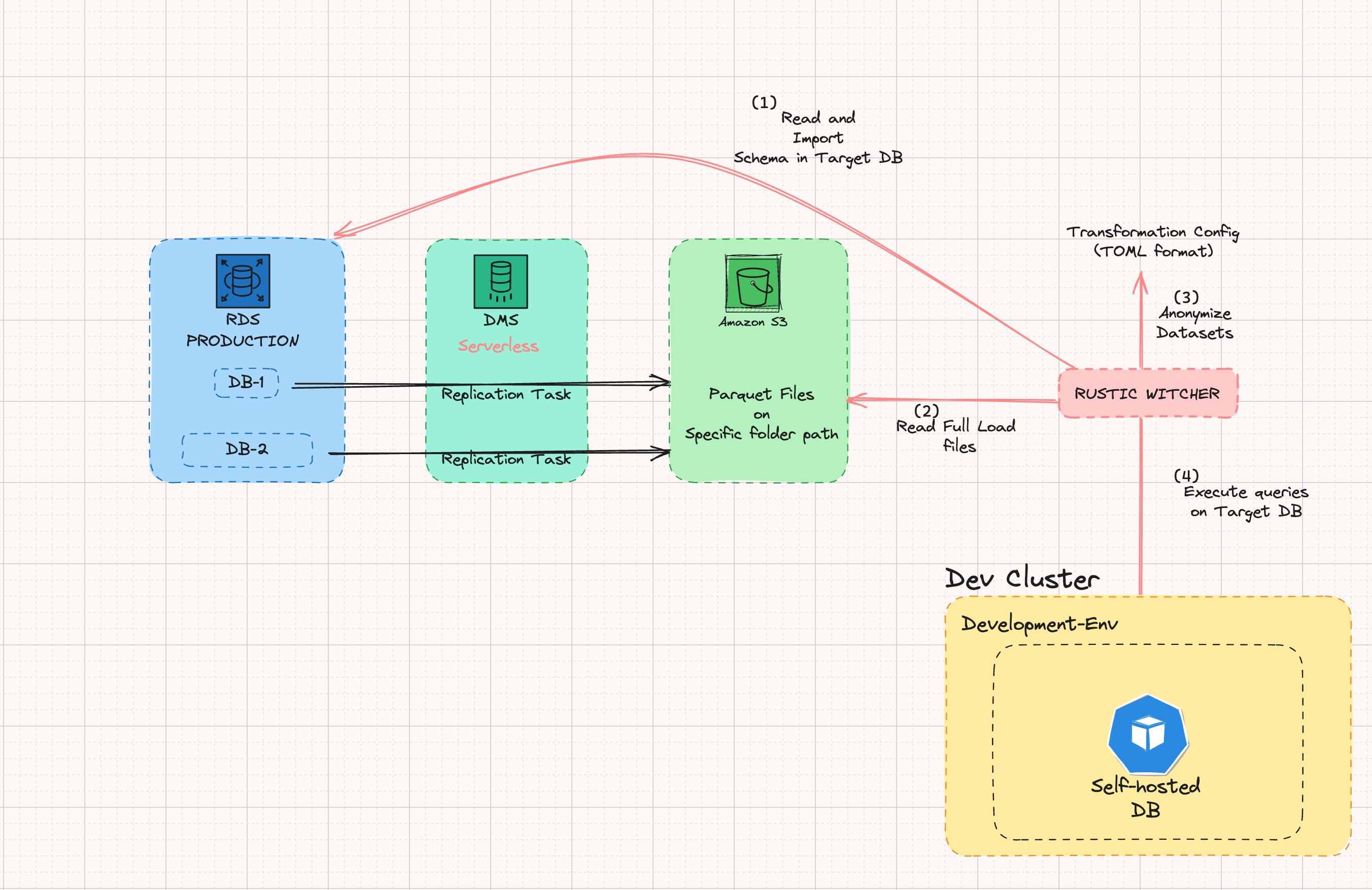
De-identification flow orchestration
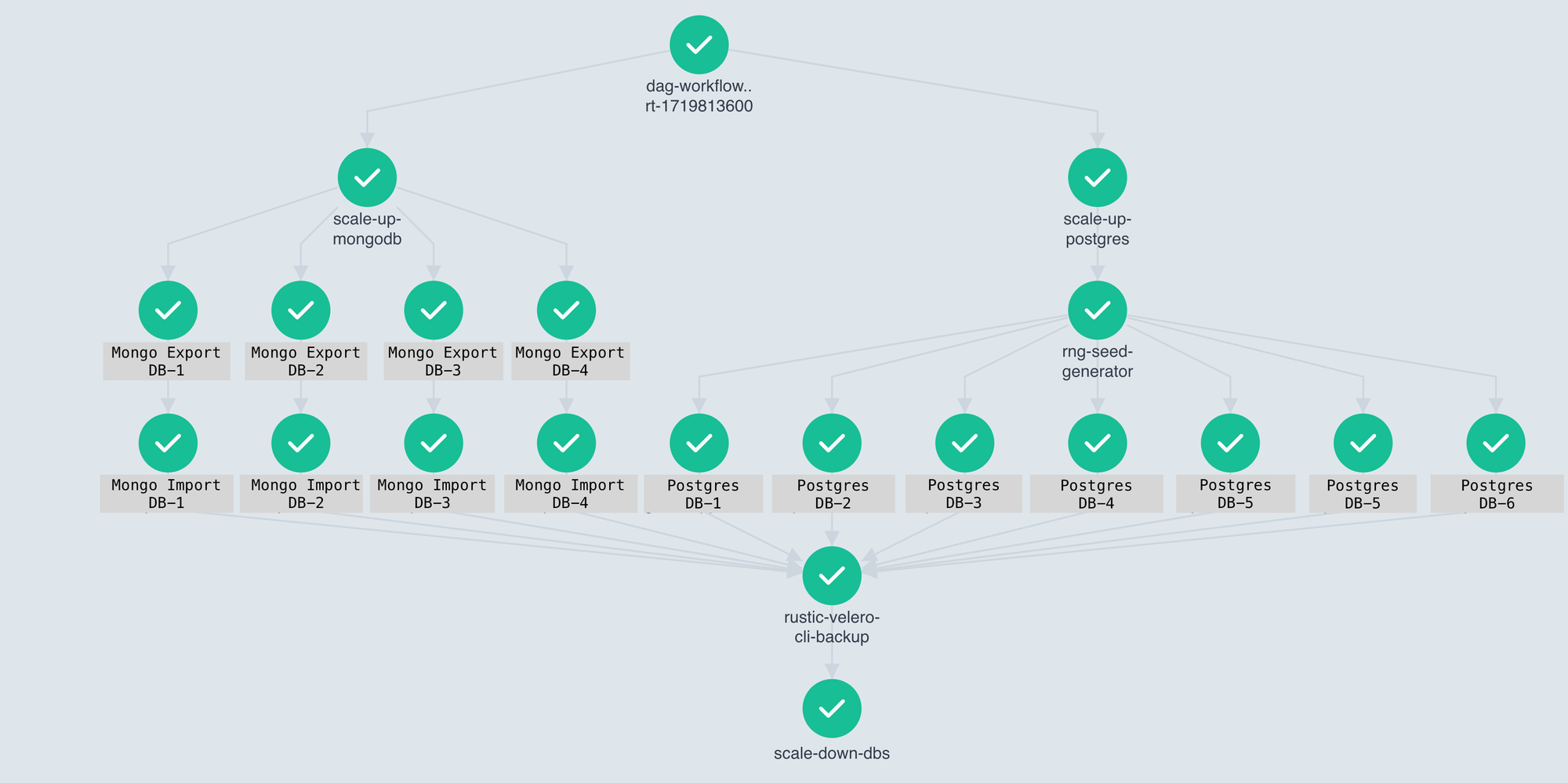
We chose to orchestrate the entire process using Argo Workflows, as it allowed us to run tasks in parallel and reuse the same workflows. The only variable in each workflow was the database-schema pair.
This workflow also supported export-import operations for our MongoDB Atlas instances, enabling us to run these processes in parallel as well.
Furthermore, we achieved a significant cost reduction of 95% compared to the previous solution. This was made possible by scaling up the datastores before the process began and scaling them down afterwards.
Finally, a Velero backup operation ensures a seamless transition from the previous solution to the new one, culminating in the same desired outcome. You can read more about how we use Velero in our "Faster Data Imports in deployment previews" blog post: https://engineering.theblueground.com/faster-data-imports-in-deployment-previews/
Improving DX
While the Platform team of Blueground's Engineering department developed this solution, which improved upon its predecessor by offering enhanced ease of debugging, we recognized the opportunity to leverage Rust's robust capabilities to further enhance the Developer Experience (DX) for our engineers.
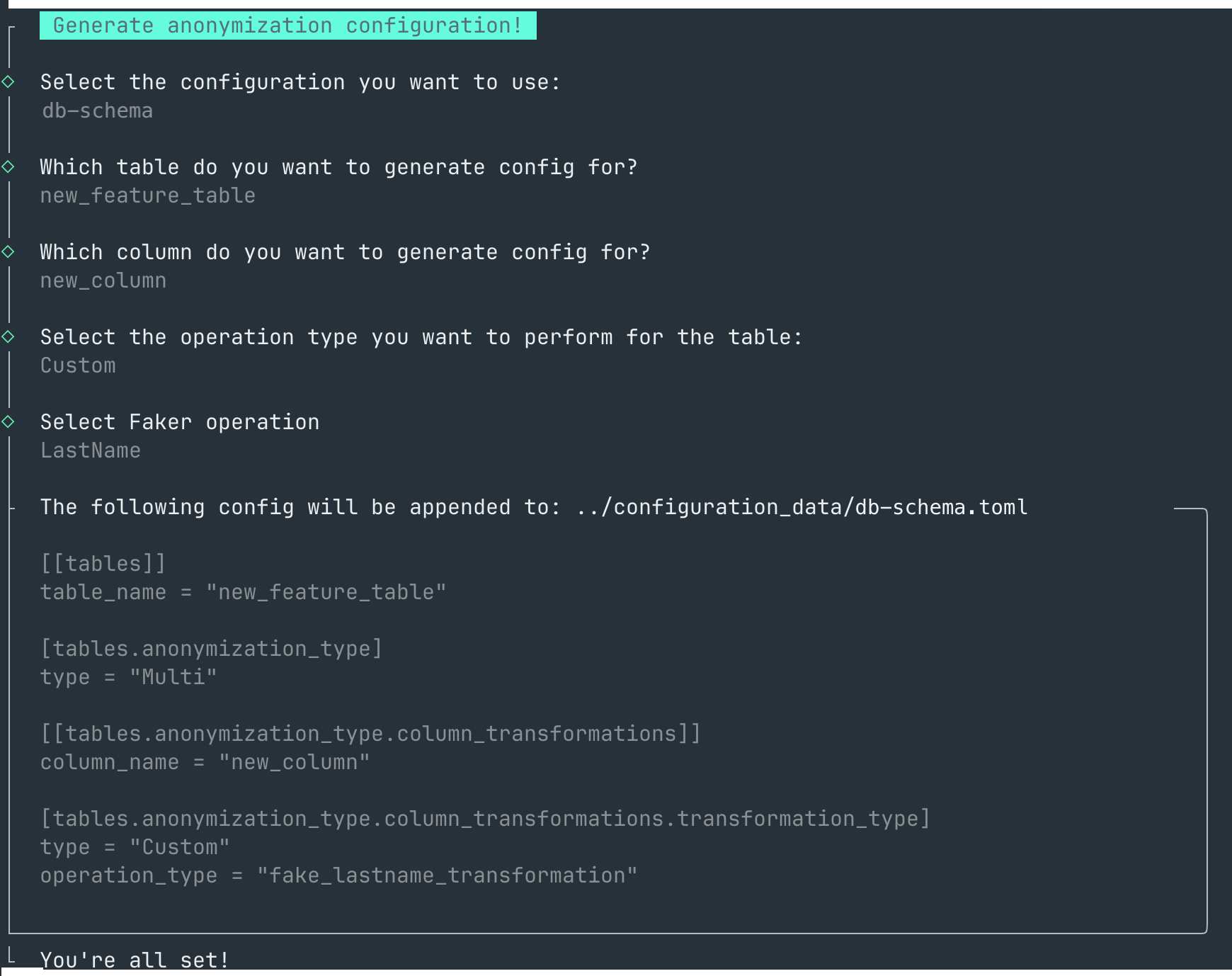
Configuration Generator
To minimize the learning curve and streamline adoption of the new solution for our engineers, we developed a CLI tool. This tool generates configuration for specified database-schema pairs directly through the terminal, eliminating the mental overhead of transitioning from the previous tool's configuration format to the new one. We anticipate that this approach will increase engagement with the new tool and empower even new hires to perform data de-identification tasks without delving into its internal workings.
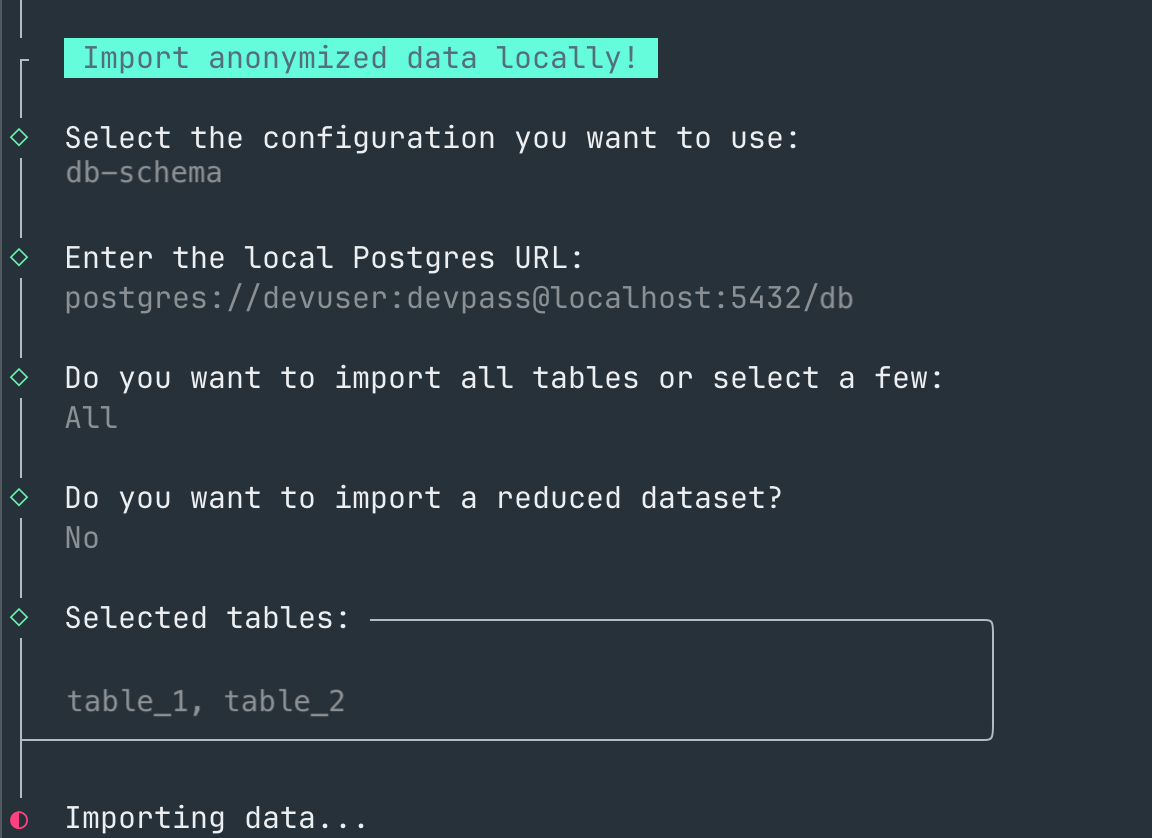
Local data import
A beneficial side-effect of implementing Rustic Witcher was the capability to write anonymized DataFrames back to .parquet files in a new S3 bucket, accessible to all engineers. This functionality was made possible by splitting Rustic Witcher into separate modules and developing a CLI tool that imports anonymized .parquet files into a local database (or any database requiring data population without schema alterations). This enhancement significantly accelerates our engineers' development process by enabling quicker data imports when starting new feature development, as opposed to manually creating data fixtures. Furthermore, considering the number of microservices involved in a typical workflow, the time savings increase incrementally.
Conclusion
The introduction of Rustic Witcher has led to significant time reductions, with an average time savings of 69.09% and a median time savings of 74.42% for the same processes.
The design and implementation of Rustic Witcher stands as a testament to the engineering excellence within Blueground's engineering department. We are enthusiastic about this new tool and look forward to further expanding its capabilities, with the potential to open-source some of its components in the future.